Amazon Bedrock telah mengumumkan kemampuan evaluasi RAG dan LLM-as-a-judge yang baru, yang menyederhanakan pengujian dan peningkatan aplikasi AI generatif. Basis Pengetahuan Amazon Bedrock kini mendukung evaluasi RAG, yang memungkinkan Anda menjalankan evaluasi basis pengetahuan otomatis untuk menilai dan mengoptimalkan aplikasi Retrieval Augmented Generation (RAG). Ini menggunakan model bahasa besar (LLM) untuk menghitung metrik evaluasi, memungkinkan perbandingan konfigurasi yang berbeda dan penyesuaian untuk hasil yang optimal. Evaluasi Model Amazon Bedrock kini menyertakan LLM-as-a-judge, yang memungkinkan pengujian dan evaluasi model lain dengan kualitas seperti manusia dengan sebagian kecil dari biaya dan waktu. Kemampuan ini menyediakan evaluasi aplikasi AI yang cepat dan otomatis, memperpendek putaran umpan balik dan mempercepat peningkatan. Evaluasi menilai dimensi kualitas seperti kebenaran, kegunaan, dan kriteria AI yang bertanggung jawab seperti penolakan jawaban dan bahaya. Hasilnya memberikan penjelasan bahasa alami untuk setiap skor, dinormalisasi dari 0 hingga 1 untuk interpretasi yang mudah. Rubrik dan petunjuk hakim dipublikasikan dalam dokumentasi untuk transparansi.
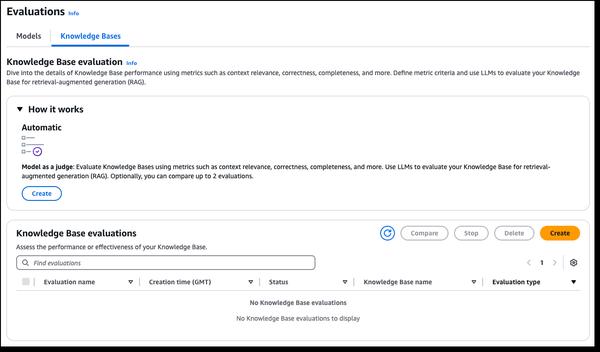
Kemampuan Evaluasi RAG dan LLM-as-a-judge Baru di Amazon Bedrock
AWS