Amazon Data Firehose memperkenalkan kemampuan baru untuk menangkap perubahan dari database seperti PostgreSQL, MySQL, dan mereplikasi pembaruan ke tabel Apache Iceberg di Amazon S3. Ini menawarkan solusi ujung ke ujung yang sederhana untuk streaming pembaruan database tanpa memengaruhi kinerja transaksi. Pengguna dapat menyiapkan aliran Data Firehose dalam hitungan menit untuk mengirimkan pembaruan penambilan data perubahan (CDC) dari database mereka. Mereka sekarang dapat dengan mudah mereplikasi data dari berbagai database ke dalam tabel Iceberg di Amazon S3 dan menggunakan data terkini untuk analitik skala besar dan aplikasi pembelajaran mesin (ML). Pelanggan perusahaan AWS biasanya menggunakan ratusan database untuk aplikasi transaksional. Untuk melakukan analitik dan ML skala besar pada data terbaru, mereka ingin menangkap perubahan yang dibuat dalam database, seperti saat rekaman disisipkan, dimodifikasi, atau dihapus dalam tabel, dan mengirimkan pembaruan ke gudang data atau danau data Amazon S3 mereka dalam format tabel sumber terbuka seperti Apache Iceberg. Banyak pelanggan mengembangkan pekerjaan ekstrak, transformasi, dan pemuatan (ETL) untuk membaca secara berkala dari database. Namun, pembaca ETL memengaruhi kinerja transaksi database, dan pekerjaan batch dapat menambah penundaan selama berjam-jam sebelum data tersedia untuk analitik. Untuk mengurangi hal ini, pelanggan ingin melakukan streaming perubahan yang dibuat dalam database, yang disebut sebagai aliran CDC. Dengan kemampuan streaming data baru ini, Data Firehose menambahkan kemampuan untuk memperoleh dan terus-menerus mereplikasi aliran CDC dari database ke tabel Apache Iceberg di Amazon S3. Pengguna menyiapkan aliran Data Firehose dengan menentukan sumber dan tujuan. Data Firehose menangkap dan mereplikasi snapshot data awal dan semua perubahan selanjutnya ke tabel database yang dipilih sebagai aliran data. Untuk memperoleh aliran CDC, Data Firehose menggunakan log replikasi database, yang mengurangi dampak pada kinerja transaksi database. Saat volume pembaruan database berfluktuasi, Data Firehose secara otomatis mempartisi data dan mempertahankan rekaman hingga pengiriman. Pengguna tidak perlu menyediakan kapasitas atau mengelola kluster. Data Firehose juga dapat secara otomatis membuat tabel Apache Iceberg menggunakan skema yang sama dengan tabel database selama pembuatan aliran awal dan secara otomatis mengembangkan skema target berdasarkan perubahan skema sumber. Sebagai layanan yang dikelola sepenuhnya, Data Firehose menghilangkan kebutuhan akan komponen sumber terbuka, pembaruan perangkat lunak, atau overhead operasional.
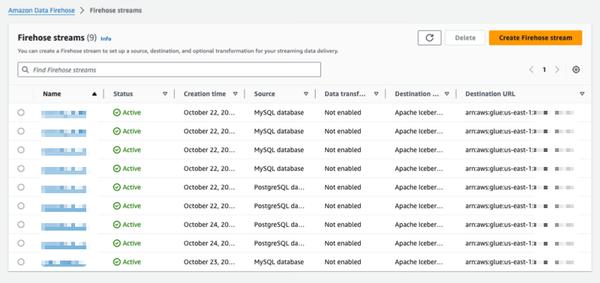
Replikasi Perubahan dari Database ke Tabel Apache Iceberg Menggunakan Amazon Data Firehose (dalam Pratinjau)
AWS