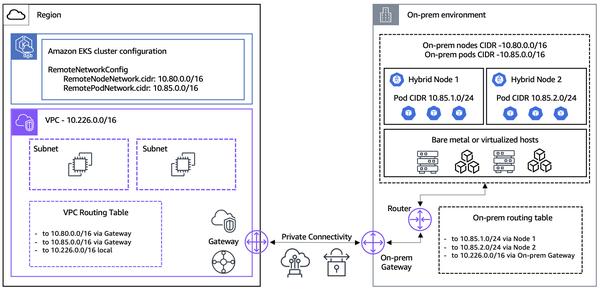
Yahoo baru-baru ini menerbitkan studi kasus yang membandingkan biaya dan kinerja menjalankan Apache Flink dan Google Cloud Dataflow untuk pipeline data skala besar. Studi tersebut menemukan bahwa Dataflow sekitar 1,5 hingga 2 kali lebih hemat biaya daripada Apache Flink yang dikelola sendiri untuk kasus penggunaan yang mereka uji.
Salah satu aspek menarik dari studi ini adalah bagaimana studi ini menyoroti pentingnya Dataflow Streaming Engine dalam mendorong pengoptimalan biaya. Streaming Engine memindahkan sebagian besar komputasi berat ke backend Dataflow, sehingga mengurangi jumlah vCPU yang diperlukan pada pekerja Dataflow. Hal ini menghasilkan pemanfaatan sumber daya yang lebih rendah dan, sebagai akibatnya, biaya yang lebih rendah.
Lebih lanjut, studi ini menekankan pentingnya konfigurasi yang cermat dan eksperimen yang berkelanjutan saat mengoptimalkan pipeline Dataflow. Model penagihan berbasis sumber daya, khususnya, ditemukan sangat efektif dalam mengoptimalkan biaya untuk beban kerja berbasis throughput.
Secara keseluruhan, studi kasus Yahoo memberikan wawasan berharga bagi organisasi yang ingin mengoptimalkan pipeline data skala besar mereka. Dengan menyoroti manfaat penghematan biaya dari Dataflow, terutama saat dipasangkan dengan Streaming Engine dan model penagihan berbasis sumber daya, studi ini menyajikan kasus yang menarik bagi perusahaan untuk mempertimbangkan Dataflow untuk kebutuhan pemrosesan data mereka.